



As AI Web Scraping becomes essential for modern data teams, rule-based scraping can no longer keep up. More engineers, analysts, and decision-makers now need smarter and more stable ways to collect information online. That’s why using Artificial Intelligence is becoming a true game-changer.
Therefore, this article from 9Proxy will show you how AI-powered automation can learn, adapt, and handle complex websites with fewer errors or interruptions. It will guide you through what AI Web Scraping is, how it works, and the best practices you can follow to collect accurate, useful, and actionable data, helping you gain a clear competitive advantage in your daily operations.

What is AI Web Scraping?
AI Web Scraping is the use of artificial intelligence (AI) to automatically collect, interpret, and refine online data in a smarter, more adaptive way than traditional rule-based scrapers. Instead of relying on fixed scripts or static XPath rules, an AI-driven system can understand website structure, recognize key elements, and adjust to layout changes without manual updates.
A modern AI setup usually includes a crawler that can load dynamic pages, a proxy rotation engine to avoid blocks, an AI selector/parser that reads data contextually, and a data pipeline to clean and deliver results. Because the model learns from feedback, AI Web Scraping becomes more accurate over time, making it a resilient and reliable solution for large-scale, complex data projects.
How AI Enhances Web Scraping?
AI enhances web scraping by adding real intelligence to a task that used to rely on brute-force rules. Instead of only reading HTML tags, the scraper can now “see” and “understand” a webpage more like a human.
Natural Language Processing (NLP)
With NLP, the system can read unstructured text such as product reviews or news articles. It automatically identifies sentiment, categorizes content, and extracts key entities like product names or dates, even when the HTML layout is inconsistent.

Computer Vision (CV)
CV is essential for scraping dynamic or visually complex websites, especially SPAs. It helps the AI detect elements such as a “Buy Now” button or a product image based on how they look and where they appear on the page, rather than depending on fragile HTML tags.
Machine Learning (ML) for Adaptability
ML models track extraction accuracy and monitor layout changes. They detect anomalies when a site prohibits requests or updates its structure, allowing the scraper to adjust parsing logic or anti-blocking methods automatically. For example, if an e-commerce site changes how prices are displayed, the AI-powered parser can learn these variations and still produce clean, consistent outputs without manual fixes.
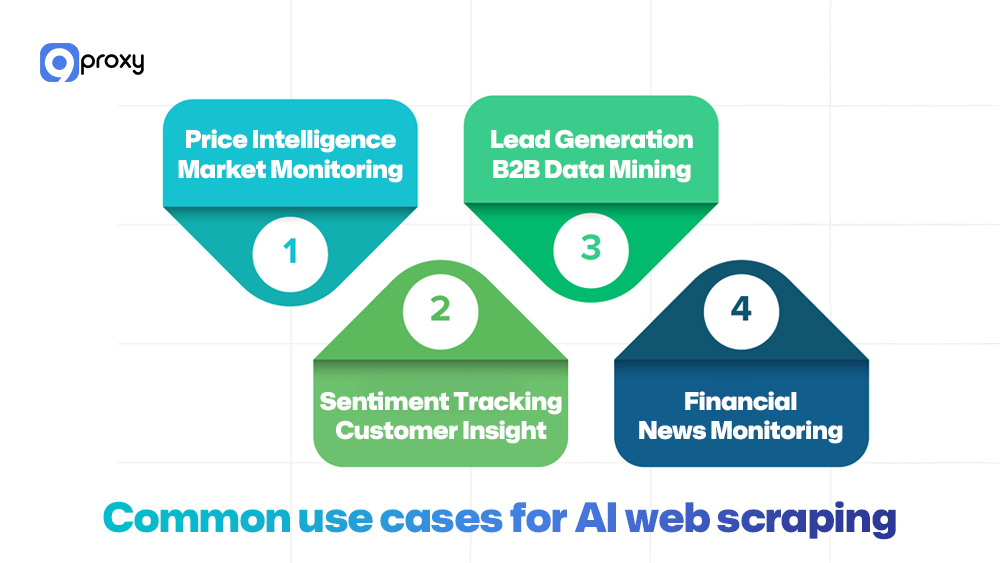
Common use cases for AI web scraping
AI Web Scraping is widely used across industries that rely on both structured and unstructured data. Below are some practical scenarios showing how it supports real-world data needs.
- Price Intelligence & Market Monitoring: AI scrapers track product prices, identify changes, and normalize formats. Businesses use them to stay competitive and quickly adjust their pricing strategies.
- Sentiment Tracking & Customer Insights: By analyzing reviews and social content, AI identifies emerging trends and customer pain points. This helps businesses improve products and support.
- Lead Generation & B2B Data Mining: AI scrapes business directories, job boards, and professional networks. In platforms with strict anti-bot systems, such as LinkedIn, an AI-powered LinkedIn scraper can classify roles, segment companies, and filter irrelevant profiles automatically while maintaining access stability.
- Financial & News Monitoring: AI-powered scrapers collect stock data, filings, and breaking news, helping analysts stay updated with fast-moving market conditions.
Differences between traditional vs AI web scraping
While both approaches focus on extracting data, the move from traditional to AI Web Scraping marks a shift from rigid rules to intelligent adaptation. Understanding this difference helps you choose the right tool for long-term, large-scale data needs.
The table below shows the key differences between a static, traditional web scraping setup and a dynamic, AI-powered web scraping solution across several important factors..
| Factor | Traditional Scraping | AI Web Scraping |
| Adaptability | Breaks after layout changes | Learns and adapts automatically |
| Data Types | Mostly structured data | Structured + unstructured + visual |
| Maintenance | High manual updates | Minimal upkeep |
| Anti-bot Handling | Basic techniques | Human-like behavior & ML-based evasion |
| Parsing Logic | Hard-coded rules | Contextual understanding |
| Scalability | Limited | High scalability through automation |
Traditional scraping is a low-cost and quick option for simple, static data tasks. However, if your project is long-term, requires high resilience, minimal maintenance, and needs to handle complex data, the adaptive intelligence of an AI Web Scraping solution is clearly the better choice.
Pros and Cons of AI web scraping
9Proxy wants you to clearly understand why many teams are shifting to AI Web Scraping. This approach offers stronger stability and better data quality, but it also requires more setup, skills, and resources. Below are the main pros and cons to help you evaluate it properly.
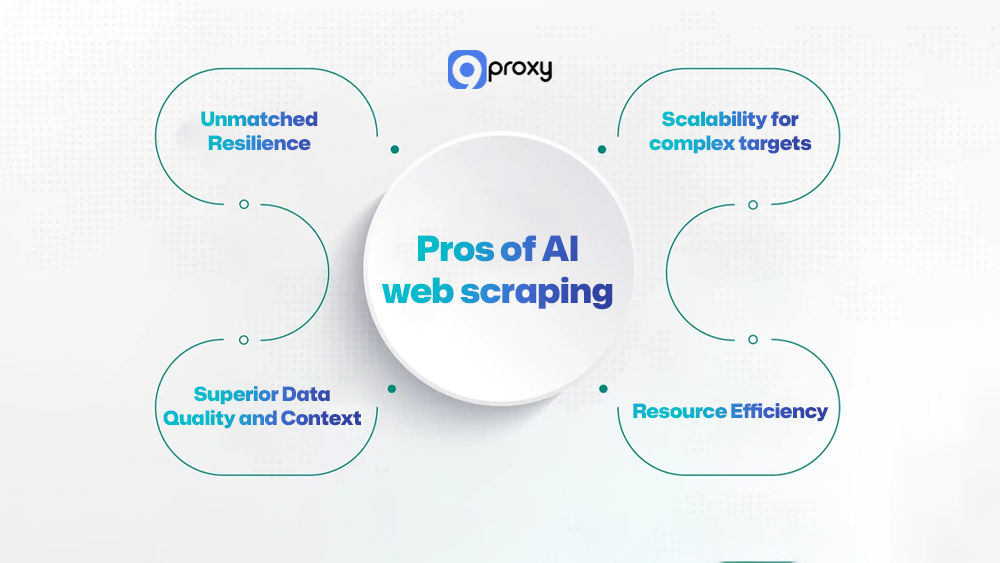
Pros of AI web scraping
AI Web Scraping offers several important advantages that can significantly improve the stability, accuracy, and efficiency of your data collection process. Below are the key benefits you should know.
- Unmatched Resilience: AI systems can detect layout changes, new anti-bot rules, and structural updates automatically. You no longer need constant developer fixes, which reduces downtime and keeps your data pipeline running smoothly.
- Superior Data Quality and Context: With NLP, the scraper understands meaning, sentiment, and relationships between data points. This produces cleaner, more consistent, and more useful datasets that are ready for analysis without heavy preprocessing.
- Scalability for Complex Targets: AI agents can handle dynamic websites, JavaScript-heavy SPAs, and inconsistent schemas that traditional scrapers often break on. This gives you access to richer and previously unreachable data sources.
- Resource Efficiency: Although setup may require more effort, long-term costs decrease because the system needs far less manual monitoring, debugging, and rule updates.
Cons of AI web scraping
Although AI Web Scraping brings many benefits, it also comes with several challenges that you should understand before choosing this approach.
- Higher Initial Complexity and Cost: AI Web Scraping needs machine learning and data science skills, so the upfront cost or tool investment is higher.
- More Computing Power Needed: AI models, especially CV models, require stronger servers or cloud resources, which increases operational costs.
- Depends on Good Training Data: If the model is trained on poor-quality data, the results will also be poor. Training quality directly affects output quality.
- Slower Per-Page Speed at First: AI spends time “thinking” and analyzing each page, so single-page extraction might be slower. The real-time savings come later because the system breaks less often.

Components of an AI-Based Scraping System
A robust, enterprise-grade AI Web Scraping system is built for scale, resilience, and high data quality. It includes several connected layers that are far more advanced than a simple script.
Data Acquisition Layer (The Crawler & Proxy):
This is where the system sends the first requests. It uses a strong headless crawler (often based on Puppeteer or Playwright) that can fully load JavaScript pages. Along with this, a resilient proxy rotation system ensures stable access. In production environments, this layer often relies on a dedicated web scraping proxy pool to distribute requests across real IPs, reduce fingerprinting risks, and maintain access consistency. At 9Proxy, this layer uses high-quality residential or mobile proxies to mimic real users and pass over anti-bot checks.
AI Selector/Parser (The Brain):
This is the main AI component. Using machine learning models trained on similar web data, it identifies and extracts the correct information. Instead of depending on a fixed XPath, it understands what a “product name” or “price” means, even when the HTML structure changes.
Preprocessing and Model Training:
Before deployment, the AI model is trained on a wide range of sample data that matches the target sites. Preprocessing involves cleaning and standardizing this training data so the model can consistently interpret different HTML layouts. Many teams build this stage using Python web scraping workflows to collect labeled samples, validate selectors, and generate training datasets that reflect real-world site variability.

Data Pipeline:
After extraction, the data goes through a pipeline for quality checks, standardization, and normalization, such as converting different price formats into one currency. It is then stored in a structured format like a database or data lake for analysis.
Feedback Loop and Continuous Improvement:
This is what makes the system intelligent. When the AI parser encounters errors or major layout changes, the issue is flagged and sent back for review. A human may check the problem, and the model is retrained. This process ensures the scraper becomes more accurate and adaptable over time.
To build and maintain these systems, we use reliable technologies such as Python, TensorFlow, or PyTorch for model training, and browser automation tools like Selenium or Playwright.
How to choose a suitable AI Web Scraping Tool?
Selecting the right tool for your AI Web Scraping needs means taking a close look at what your project requires. Because these systems are complex, choosing the wrong solution can lead to slow performance, high costs, or unreliable results.
When evaluating tools, focus on these five important criteria:
- Speed and Volume Capacity: The tool should handle your expected data load while keeping extraction speeds stable, even with AI processing.
- Accuracy and Adaptability: Check how well the AI reacts to website changes. A good system should adjust automatically when a layout shifts. Its accuracy on different dynamic sites helps you measure real reliability.
- Integration and Data Output: Your chosen solution must fit smoothly into your current data workflow. It should support clean, standardized formats like JSON or CSV and offer simple API integration.
- Cost Structure: Look beyond the basic pricing. Consider request costs, proxy expenses, and computing resources. A cheaper tool that breaks often and drains developer time will cost more in the long run.
- Anti-Blocking and Proxy Management: Even the best scraper is useless if it can’t access the website. Choose a tool with strong anti-bot features and intelligent proxy rotation.

Top 6 AI Web Scraping Tools You Should Know
The market for intelligent data extraction is maturing quickly, offering strong commercial and open-source options. Here are six leading AI Web Scraping tools and platforms we consider top-tier:
Diffbot
Diffbot is one of the most advanced AI Web Scraping platforms on the market, known for its AI-driven computer vision and NLP capabilities. Instead of relying on HTML rules, Diffbot reads a webpage visually in a way similar to how a human would and identifies entities such as products, articles, organizations, people, or events. It maps relationships between these entities and automatically converts them into structured knowledge graph data.
- Pros: Excellent accuracy, fully automated end-to-end extraction, strong knowledge graph integration.
- Cons: Higher cost compared to standard scraping tools.
- When to use: Enterprise-level data extraction that requires near-human interpretation and large-scale knowledge graph building.
ScrapingBee AI
ScrapingBee AI is a lightweight, API-based scraping solution designed for simplicity and speed. It handles JavaScript rendering, dynamic content, and rotating proxies in the background while offering an AI-enhanced parsing engine that adapts to common layout changes. Developers can send a single API request to retrieve clean, structured data without managing infrastructure.
- Pros: Very easy to set up, stable performance, minimal configuration required.
- Cons: Limited customization options for complex or non-standard websites.
- When to use: Lightweight commercial projects, quick integrations, and use cases where you need fast, reliable results without heavy engineering work.
Zyte AutoExtract
Zyte AutoExtract delivers structured data using machine learning models trained on millions of real web pages. Instead of extracting raw HTML, the service returns structured data types such as product details, article metadata, or real estate listings through a clean API.
- Pros: High-quality structured outputs with minimal effort.
- Cons: Dependent on predefined extraction endpoints, which reduces flexibility on unusual page types.
- When to use: E-commerce price monitoring, real estate listing extraction, or workflows that require standardized data formats.

Browse AI
Browse AI is a no-code tool that allows users to create scraping workflows visually by showing the AI what to extract. It can track changes, detect repeated patterns, and classify basic information without requiring programming knowledge.
- Pros: Easy for non-engineers, intuitive interface, fast setup with no coding.
- Cons: Less suitable for large-scale or highly dynamic systems that need complex logic.
- When to use: Small to mid-size workflows, monitoring dashboards, and simple data extraction tasks for marketing, operations, or research.

Apify AI Crawler
Apify AI Crawler combines API capabilities, JavaScript customization, and AI recognition. Developers can build advanced Actors, which are serverless scraping applications that use AI to detect patterns, extract complex data, and run automated crawling jobs at scale.
- Pros: Flexible, developer-friendly, suitable for custom logic and complex dynamic websites.
- Cons: Requires technical skills to configure and optimize.
- When to use: Large-scale and complex scraping tasks that require custom workflows, JavaScript-based logic, or advanced AI selectors.
Octoparse AI Mode
Octoparse AI Mode is a visual scraping tool built to simplify data extraction for beginners. Its AI-powered auto-detection can identify common fields such as prices, titles, images, and descriptions across many websites. Users can create scraping templates quickly, making it ideal for simple data tasks or early-stage prototypes.
- Pros: Beginner-friendly, fast template creation, no coding required.
- Cons: Limited performance on dynamic, irregular, or JavaScript-heavy sites.
- When to use: Quick prototyping, small business data needs, and simple scraping tasks that do not require deep customization.
Free vs. Commercial AI Web Scraping Solutions
Free or open-source solutions offer flexibility and transparency but require technical expertise to manage updates, proxies, and anti-bot challenges. While commercial solutions handle infrastructure for you, but may come with higher licensing fees. The choice between a free, open-source solution and a commercial, managed service is a trade-off between having full control and enjoying greater convenience.
| Feature | Open-Source/Free Solutions | Commercial/Managed Solutions |
| Initial Cost | Low (Libraries are free) | High (Subscription/Per-Request Fees) |
| Maintenance/Effort | Very High (You manage the code, proxies, and fixes) | Low (The vendor manages infrastructure and code updates) |
| Adaptability & Resilience | Highly dependent on in-house coding skills; can be brittle. | High (The vendor’s team ensures continuous, dedicated anti-blocking and parsing support.) |
| Time-to-Market | Slow (Requires development and testing of all components) | Fast (Ready-to-use APIs and platforms) |
We recommend using a commercial solution if your business needs a steady and reliable stream of data, such as price monitoring or financial feeds. The time saved on developer work and the guaranteed uptime usually make the subscription cost worthwhile. On the other hand, choose a free solution if the data is only for internal research and your developers have enough time to handle maintenance and disable evasion themselves.
How to Keep Your AI Web Scraper Effective?
Even though AI is smart, an AI Web Scraping system still needs proper care to keep it running well and to avoid legal or ethical problems. Long-term success depends on good planning and regular checks.
Best Practice Guidance
To keep your AI Web Scraping system running smoothly, you need the right management practices. Below are essential steps that help maintain accuracy, reduce errors, and ensure your scraping activities remain stable, efficient, and compliant over time.
- Use a Human-in-the-Loop (HITL): AI can adjust to many changes, but big website updates or new anti-bot tools still need human review. A HITL setup helps the AI flag unusual drops in data quality so a human can check and retrain the model quickly.
- Set and Follow a Clear Monitoring Schedule: Decide how often your data must be updated, such as hourly for finance or daily for product reviews. Stick to this schedule to avoid unnecessary scraping and reduce server load.
- Validate Data Continuously: Make sure your pipeline checks the meaning of the data, not just the structure. For example, a “price” field should contain a real number, not text like “contact us.”
- Respect robots.txt and TOS: Always read the website’s robots.txt file and follow its rules. Also, review the Terms of Service to make sure your scraping activity is allowed.

Tips for Long-Term Scraping Operations
To keep your AI Web Scraping system reliable in the long run, you need strategies that reduce prohibiting and improve efficiency. The tips below help you maintain stable access, protect resources, and ensure your scraping operations continue running smoothly over time.
- Use a Diverse Proxy Pool: Never depend on a single IP. A large mix of residential and mobile proxies, like those from 9Proxy, helps maintain stable access and reduces errors.
- Mimic Real User Behavior: Train the AI to behave like a normal user by randomizing headers, scrolling, clicking, and adding wait times. Avoid sending too many requests too quickly.
- Use Caching Wisely: Cache pages that rarely change. Only scrape again when needed to save resources and reduce pressure on the target website.
Challenges & Ethical Considerations
When performing large-scale AI Web Scraping, it is important to follow legal rules and ethical standards. This protects your business and helps maintain a healthy web environment.
Legal and Compliance Concerns (GDPR, CCPA, TOS):
Scraping public data is generally legal, but collecting private or copyrighted content without permission is not. Always respect TOS and follow privacy laws like GDPR and CCPA.
Website Load and Server Strain:
Scraping too aggressively can overload a small website. Use crawl delays and off-peak scheduling to avoid causing issues.
Ethical Scraping and Responsible AI Use:
Ethical scraping means avoiding harmful behavior, such as gathering sensitive data or scraping competitors unfairly. Ensure scraped data is not used to create biased AI models.
Combatting Bias in Scraped Data:
AI models reflect the data they learn from. If the scraped data is biased, the AI will be biased too. Always check datasets for balanced and diverse information.

FAQ
Can AI scraping go around CAPTCHA?
Yes. Some advanced AI Web Scraping systems can skip CAPTCHA, such as reCAPTCHA v3 and HCaptcha. They do this using machine learning to solve visual challenges, third-party CAPTCHA services, or by using high-quality residential proxies that avoid these challenges entirely.
Is AI scraping legal?
The legality of AI Web Scraping depends on the type of data and your scraping method. Scraping publicly available, non-copyrighted information is generally allowed. However, collecting private, restricted, or copyrighted data or violating a site’s TOS can result in legal issues. Always follow robots.txt and seek legal advice when needed.
What skills are needed to build an AI scraper?
Building an in-house AI Web Scraping system requires several skills, including Python programming for core logic, experience in Machine Learning (ML) and Natural Language Processing (NLP) for the parser, and a strong understanding of web protocols and browser automation for the crawler.
What should businesses consider before adopting AI web scraping?
Businesses should consider the Total Cost of Ownership (TCO), including compute and maintenance costs beyond subscription fees. They should also review data governance to ensure legal and ethical compliance, and evaluate scalability to confirm the system can grow with their data needs and can be supported by a strong proxy provider like 9Proxy.
Conclusion
The evolution to AI Web Scraping is more than just a technical improvement; it is a strategic shift that turns raw online data into a dependable, high-quality, and actionable business resource. By moving from fragile, rule-based scrapers to intelligent, adaptive, and self-correcting systems, you keep your data flowing smoothly even as websites constantly change. This blog has explained what AI Web Scraping is, how it works, and the key best practices for using it effectively.
To protect your high-volume and long-term scraping operations, the most important infrastructure you need is a strong, diverse proxy network. Contact 9Proxy today to explore the residential proxies your AI Web Scraping projects require.






