


Web scraping (thu thập dữ liệu web) là quá trình tự động sử dụng phần mềm hoặc “bot” để trích xuất dữ liệu từ các trang web. Quá trình này bao gồm gửi yêu cầu truy cập trang web, phân tích cú pháp HTML để tìm thông tin cụ thể và lưu trữ dữ liệu phục vụ phân tích, thường là trong bảng tính hoặc cơ sở dữ liệu. Các ứng dụng phổ biến của web scraping bao gồm: nghiên cứu thị trường, so sánh giá và tạo danh sách khách hàng tiềm năng.
Trong bài hướng dẫn này, 9Proxy sẽ cùng bạn khám phá những thư viện Python phổ biến và hiệu quả nhất cho web scraping. Từ những công cụ đơn giản cho nhu cầu cơ bản đến các framework nâng cao cho dự án lớn, bài viết sẽ giúp bạn so sánh và chọn giải pháp phù hợp nhất. Sau khi đọc xong, bạn sẽ hiểu rõ cách xây dựng quy trình scraping ổn định và có khả năng mở rộng nhờ hệ sinh thái Python linh hoạt.

Web Scraping Trong Python Là Gì?
Web scraping trong Python là quá trình tự động trích xuất dữ liệu từ trang web bằng các script Python. Nó bao gồm lấy nội dung HTML và phân tích để thu thập thông tin cụ thể như giá sản phẩm, đánh giá hoặc tiêu đề bài viết.
Nhờ cú pháp đơn giản và hệ thống thư viện mạnh mẽ, Python là lựa chọn lý tưởng cho cả người mới bắt đầu lẫn người dùng nâng cao khi làm việc với các trang web tĩnh hoặc nội dung động (được tải bằng JavaScript).

Khi làm web scraping, bạn thường phải xử lý cả trang tải sẵn lẫn phần nội dung chỉ hiện ra sau khi trang chạy JavaScript. Python có nhiều công cụ nên bạn dễ chọn đúng cái mình cần, từ lấy giá sản phẩm, theo dõi đối thủ cho đến thu thập dữ liệu nghiên cứu.
Top 9 Công Cụ Và Thư Viện Web Scraping
Urllib3
Urllib3 là một HTTP client mạnh mẽ tích hợp trong Python, phù hợp cho các nhu cầu scraping cơ bản. Nếu bạn muốn kiểm soát chi tiết các yêu cầu HTTP và làm việc ở mức thấp, đây là lựa chọn phù hợp.
- Ưu điểm: Hỗ trợ connection pooling (tái sử dụng kết nối), xác thực SSL, và hỗ trợ proxy. Nhờ đó bạn có thể gửi yêu cầu đến trang web an toàn và hiệu quả hơn.
- Nhược điểm: Không phân tích HTML hoặc JavaScript, vì thế thường phải kết hợp với công cụ khác như BeautifulSoup.
- Khi nào nên dùng? Khi bạn cần kiểm soát chi tiết request HTTP hoặc cần lấy dữ liệu thô một cách an toàn.

BeautifulSoup
BeautifulSoup là một trong những thư viện phổ biến nhất để phân tích HTML và XML. Nó chuyển đổi HTML phức tạp thành cấu trúc dễ điều hướng, giúp trích xuất dữ liệu đơn giản hơn.
- Ưu điểm: Có API đơn giản, dễ sử dụng cho người mới, xử lý tốt HTML lỗi.
- Nhược điểm: Chậm hơn những framework mạnh như Scrapy khi xử lý dữ liệu quy mô lớn
- Khi nào nên dùng? Phù hợp cho dự án nhỏ đến trung bình, tập trung vào phân tích trang tĩnh.

Requests
Requests là thư viện HTTP phổ biến nhờ API gọn gàng và dễ sử dụng. Nó xử lý cookie, xác thực và redirect tự động, giúp lập trình viên tập trung vào logic scraping thay vì chi tiết giao thức HTTP.
- Ưu điểm: Rất dễ sử dụng, cú pháp sạch, tài liệu đầy đủ. Nó xử lý hiệu quả tiêu đề, cookie và phiên làm việc.
- Nhược điểm: Tương tự Urllib3, thư viện này không hỗ trợ phân tích hay JavaScript. Vì thế vẫn cần kết hợp công cụ khác.
- Khi nào nên dùng? Kết hợp với BeautifulSoup hoặc lxml để scraping nhanh các trang tĩnh.

MechanicalSoup
MechanicalSoup đóng vai trò như cầu nối giữa trình duyệt và script Python. Thư viện này cung cấp các API cấp cao, cho phép mô phỏng thao tác người dùng như điền form, nhấn nút, hay điều hướng trang. MechanicalSoup tổng hòa các ưu điểm của Requests và BeautifulSoup.
- Ưu điểm: Tự động hóa điền form, quản lý cookie, và điều hướng giữa các trang.
- Nhược điểm: Không phù hợp cho trang nhiều JavaScript. Thích hợp hơn với các tương tác đơn giản.
- Khi nào nên dùng? Khi bạn thu thập các loại dữ liệu cần đăng nhập hoặc gửi biểu mẫu đơn giản.

Selenium
Selenium là một công cụ mạnh mẽ, ban đầu được phát triển cho mục đích tự động hóa và kiểm thử trình duyệt. Nó có thể điều khiển các trình duyệt như Chrome, Firefox hoặc Safari, cho phép script mô phỏng hành vi người dùng thật, từ nhấp chuột, điền biểu mẫu cho đến cuộn trang. Nhờ khả năng này, Selenium đặc biệt phù hợp để thu thập dữ liệu từ các website sử dụng nhiều JavaScript hoặc có tương tác phức tạp.
- Ưu điểm: Có thể tương tác trực tiếp với các thành phần JavaScript, mô phỏng thao tác người dùng, hỗ trợ xử lý tải file
- Nhược điểm: Nặng và chậm hơn so với các phương pháp trên trang tĩnh. Tiêu tốn nhiều tài nguyên hệ thống.
- Khi nào nên dùng? Sử dụng Selenium khi nội dung website được tải động thông qua JavaScript hoặc khi bạn cần mô phỏng thao tác người dùng thực tế.

Pandas
Pandas là một thư viện phân tích dữ liệu, đặc biệt hữu ích sau khi bạn đã thu thập được dữ liệu thô từ website. Với hàm read_html(), Pandas có thể đọc trực tiếp bảng HTML và chuyển đổi thành DataFrame có cấu trúc rõ ràng. Ngoài thu thập, Pandas còn rất mạnh trong việc làm sạch, chuyển đổi và phân tích dữ liệu, nên thường được sử dụng ở giai đoạn xử lý dữ liệu sau khi thu thập.
- Ưu điểm: Xử lý và biến đổi dữ liệu mạnh mẽ. Dễ dàng xuất dữ liệu sang CSV, Excel hoặc lưu vào cơ sở dữ liệu.
- Nhược điểm: Không tự thực hiện việc gửi request hay thu thập dữ liệu
- Khi nào nên dùng? Dùng Pandas sau bước scraping để định dạng, làm sạch và phân tích dữ liệu thu thập được.

ZenRows
ZenRows là một API web scraping giúp đơn giản hóa việc xử lý các cơ chế chống bot và quản lý proxy. Dịch vụ này hỗ trợ xoay vòng proxy, giải CAPTCHA, render JavaScript và vượt qua các hệ thống chống bot thông qua một API thống nhất.
- Ưu điểm: Tự động xử lý render JavaScript. hỗ trợ xoay vòng proxy, có thể vượt qua các cơ chế anti-bot và CAPTCHA
- Nhược điểm: Bản miễn phí có giới hạn và có thể cần đăng ký gói trả phí cho dự án quy mô lớn
- Khi nào nên dùng? Phù hợp cho các dự án scraping ở mức production, đặc biệt khi website có cơ chế chống bot nghiêm ngặt.

Playwright
Playwright là một framework tự động hóa trình duyệt hiện đại do Microsoft phát triển, hỗ trợ nhiều trình duyệt headless như Chromium, Firefox và WebKit. Playwright có khả năng xử lý nội dung động và các tương tác phức tạp. Ngoài ra, nó còn cung cấp các tính năng nâng cao như chặn, theo dõi request mạng (network interception) và cô lập ngữ cảnh trình duyệt (context isolation).
- Ưu điểm: Tải trang nhanh hơn Selenium, hỗ trợ tốt các tính năng JavaScript hiện đại, tương thích với nhiều trình duyệt
- Nhược điểm: Khá khó dùng đối với người mới
- Khi nào nên dùng? Rất phù hợp để thu thập dữ liệu từ các website hiện đại, có nhiều tương tác và phụ thuộc nhiều vào JavaScript.

Scrapy
Scrapy là một framework web scraping được thiết kế dành riêng cho các dự án quy mô lớn và chuyên nghiệp. Nó cung cấp gần như mọi thứ bạn cần để thu thập dữ liệu web, từ việc duyệt qua nhiều trang, lấy dữ liệu, cho đến xử lý và lưu trữ thông tin.
- Ưu điểm: Có sẵn công cụ để tự động truy cập và thu thập dữ liệu từ nhiều trang, hỗ trợ xử lý và xuất dữ liệu một cách có hệ thống, hoạt động nhanh và hiệu quả.
- Nhược điểm: Cài đặt và cấu hình phức tạp hơn, không thân thiện với người mới bằng BeautifulSoup hoặc Requests.
- Khi nào nên dùng? Sử dụng Scrapy khi bạn cần thu thập dữ liệu từ nhiều trang hoặc xây dựng hệ thống scraping quy mô lớn.

Cách Chọn Thư Viện Phù Hợp
Việc lựa chọn công cụ phù hợp phụ thuộc vào nhu cầu cụ thể của bạn. Bảng so sánh dưới đây sẽ giúp bạn dễ dàng đưa ra quyết định:
| Thư viện | Phù hợp nhất cho | Hỗ trợ JavaScript | Độ khó học | Phù hợp cho người mới |
| Urllib3 | Gửi request HTTP cơ bản | Không | Thấp | Có |
| BeautifulSoup | Phân tích HTML tĩnh | Không | Thấp | Có |
| MechanicalSoup | Tương tác đơn giản (form, đăng nhập) | Không | Thấp | Có |
| Requests | Gửi request web dễ dàng | Không | Thấp | Có |
| Selenium | Nội dung JavaScript động | Có | Trung bình | Có |
| Pandas | Phân tích và định dạng dữ liệu | Không áp dụng | Thấp | Có |
| ZenRows | Vượt cơ chế chống bot | Có | Thấp | Có |
| Playwright | Tự động hóa trình duyệt nhanh | Có | Trung bình | Có |
| Scrapy | Dự án scraping quy mô lớn | Hạn chế | Cao | Không |
Tùy vào mức độ phức tạp của dự án, 9Proxy khuyến nghị bạn nên bắt đầu với Requests + BeautifulSoup, sau đó nâng cấp lên Playwright hoặc Scrapy khi cần xử lý các yêu cầu nâng cao hơn. Ngoài ra, bạn cũng có thể lựa chọn dựa trên loại website (trang tĩnh hay nội dung động), quy mô dự án, yêu cầu kỹ thuật và mức độ tự động hóa
Để hỗ trợ quá trình scraping hiệu quả hơn, bạn cũng có thể tham khảo thêm nstbrowser, một công cụ cung cấp nhiều thông tin hữu ích về cách tự động hóa quá trình duyệt web.
Ứng Dụng Thực Tế Của Web Scraping
Web scraping bằng Python không chỉ dành cho lập trình viên. Đây là giải pháp thực tế cho bất kỳ ai cần thu thập dữ liệu web ở quy mô lớn.
Một số ứng dụng phổ biến bao gồm:
- Phân tích đối thủ cạnh tranh: Theo dõi thay đổi về giá, sản phẩm hoặc chiến lược nội dung.
- So sánh giá: Thu thập dữ liệu giá từ nhiều nền tảng thương mại điện tử.
- Tạo danh sách khách hàng tiềm năng: Trích xuất email, số điện thoại từ danh bạ công khai.
- Phân tích cảm xúc (Sentiment Analysis): Thu thập đánh giá hoặc bài đăng mạng xã hội để phân tích quan điểm người dùng.
- Phân tích mạng xã hội: Theo dõi hashtag, xu hướng hoặc mức độ tương tác.
- Nghiên cứu & báo chí: Thu thập dữ liệu có cấu trúc phục vụ nghiên cứu học thuật hoặc theo dõi tin tức.
Những ứng dụng này cho thấy web scraping có thể hỗ trợ cả chiến lược kinh doanh lẫn nghiên cứu dữ liệu chuyên sâu.

Các Bước Hướng Dẫn Xây Dựng Web Scraper
Giờ bạn đã hiểu mình có thể làm gì với web scraping, hãy cùng tìm hiểu cách xây dựng một công cụ thu thập dữ liệu hoàn chỉnh. Chúng tôi sẽ hướng dẫn bạn từng bước quan trọng, từ khâu chuẩn bị đến xử lý các vấn đề thường gặp.
Chuẩn Bị Cho Quá Trình Web Scraping
Trước khi viết code, bạn cần chuẩn bị tốt môi trường thực hiện bằng cách:
- Cài đặt Python 3 và đảm bảo đã thêm vào PATH
- Tạo môi trường ảo (venv hoặc virtualenv) để quản lý các dependency
- Cài đặt các thư viện cần thiết, như: pip install requests beautifulsoup4 scrapy selenium pandas
Việc này giúp đảm bảo dự án hoạt động ổn định và tránh xung đột giữa các thư viện.

Quy Trình Thực Hiện Web Scraping
Việc xây dựng một công cụ thu thập dữ liệu thường gồm một số bước rõ ràng. Dưới đây là cách chúng ta thực hiện từng bước:
Bước 1: Xác định dữ liệu mục tiêu
Sử dụng công cụ “Inspect” (Kiểm tra phần tử) trên trình duyệt để xác định chính xác vị trí dữ liệu trên trang. Bạn cần xem dữ liệu nằm trong thẻ <div>, thuộc một class cụ thể, hay được tải lên sau khi trang chạy JavaScript.

Bước 2: Gửi yêu cầu truy cập trang web
Sử dụng thư viện requests để tải nội dung trang:
import requests
response = requests.get(“https://example.com”)

Trong một số trường hợp, đặc biệt khi tải xuống tệp hoặc làm việc với công cụ dòng lệnh, lập trình viên có thể cấu hình wget proxy kết hợp với proxy để chuyển yêu cầu qua máy chủ trung gian một cách an toàn.
Bước 3: Phân tích nội dung trang
Sử dụng BeautifulSoup để chuyển nội dung HTML sang dạng có thể xử lý và truy xuất:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, ‘html.parser’)

Bước 4: Trích xuất dữ liệu cụ thể
Dùng các phương thức như .find() hoặc .find_all() để lấy đúng phần thông tin mong muốn:
titles = soup.find_all(“h2″, class_=”title”)

Bước 5: Lưu trữ dữ liệu
Sau khi đã lấy được dữ liệu, bạn có thể lưu dưới dạng tệp CSV bằng module csv có sẵn trong Python hoặc sử dụng pandas để xử lý linh hoạt hơn:
import pandas as pd
df = pd.DataFrame(titles)
df.to_csv(“output.csv”, index=False)

Bước 6: Thêm xử lý cho nhiều trang
Để thu thập dữ liệu từ nhiều trang, bạn cần thêm logic xử lý phân trang hoặc các nút “Load more”. Điều này có thể thực hiện bằng vòng lặp hoặc gọi lại hàm nhiều lần (đệ quy).
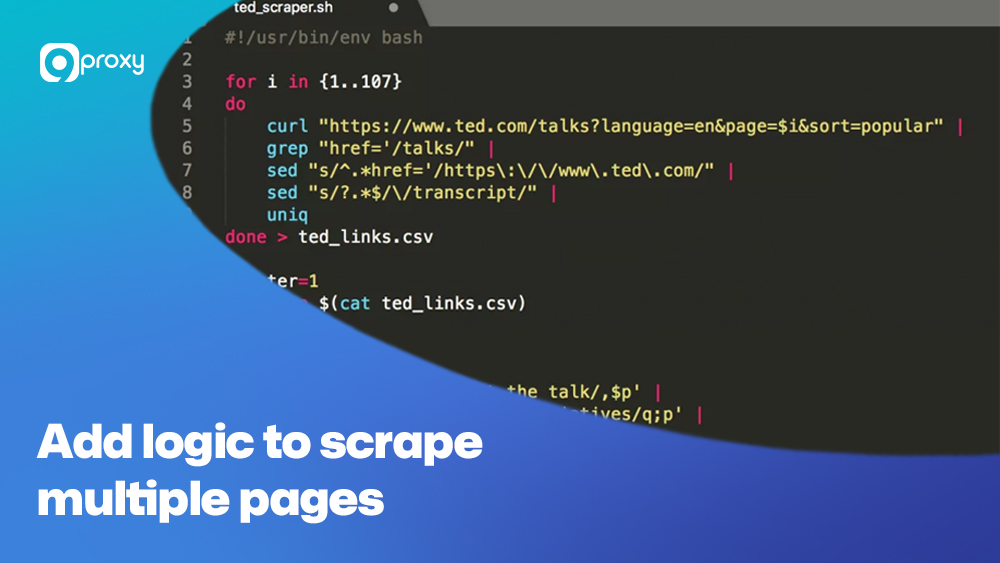
Với quy trình này, ngay cả những website có quy mô lớn cũng có thể được thu thập dữ liệu một cách có hệ thống, với mã nguồn gọn gàng và có thể tái sử dụng cho các dự án sau.
Xử Lý Các Vấn Đề Thường Gặp
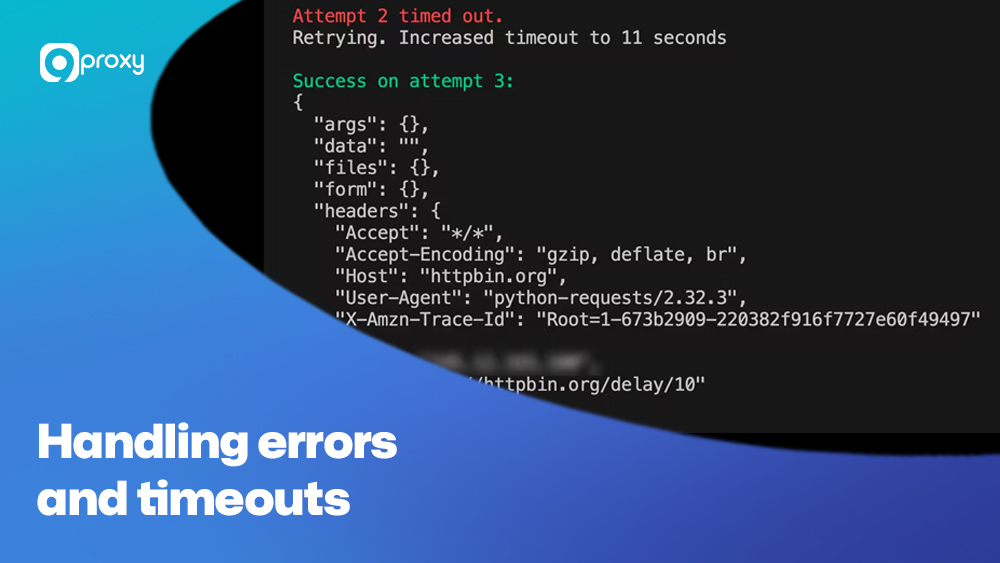
Giải quyết lỗi và tình trạng hết thời gian chờ
Khi thu thập dữ liệu từ web, bạn rất dễ gặp phải các vấn đề như kết nối bị gián đoạn, lỗi 403 (bị từ chối truy cập) hoặc trang phản hồi quá chậm dẫn đến hết thời gian chờ. Để chương trình hoạt động ổn định hơn, bạn nên sử dụng cấu trúc xử lý ngoại lệ, thêm cơ chế thử lại khi gặp lỗi và chèn khoảng nghỉ giữa các lần gửi yêu cầu.
import time
from requests.exceptions import RequestException
try:
response = requests.get(url)
except RequestException:
time.sleep(5)
Tránh Bị Chặn Địa Chỉ IP
Nhiều website có hệ thống phát hiện và ngăn chặn công cụ tự động thu thập dữ liệu. Để hạn chế bị nhận diện và khóa truy cập, bạn có thể:
- Sử dụng dịch vụ proxy chuyên cho thu thập dữ liệu (chẳng hạn như các giải pháp từ 9Proxy)
- Thêm thông tin tiêu đề truy cập (header) và giả lập trình duyệt thông qua User-Agent
- Tạo khoảng nghỉ ngẫu nhiên giữa các lần gửi yêu cầu
- Sử dụng VPN hoặc mạng Tor để tăng mức độ ẩn danh
Proxy đặc biệt hữu ích khi bạn cần mở rộng quy mô thu thập dữ liệu. Chúng giúp giảm nguy cơ bị chặn, hạn chế xuất hiện mã xác minh (CAPTCHA) và tránh việc địa chỉ IP bị cấm truy cập.
Kết Luận
Web scraping trong Python mang đến một phương pháp linh hoạt và có khả năng mở rộng để thu thập dữ liệu trên internet. Với các thư viện thân thiện như Requests và BeautifulSoup, đến những công cụ nâng cao như Playwright hoặc Scrapy, bạn hoàn toàn có thể xây dựng hệ thống scraping từ đơn giản đến phức tạp.
9Proxy tin rằng proxy chính là chìa khóa giúp quá trình thu thập dữ liệu diễn ra ổn định và an toàn. Dù bạn đang theo dõi giá, tìm kiếm khách hàng tiềm năng hay phân tích xu hướng cảm xúc, việc kết hợp đúng công cụ với đúng loại proxy sẽ giúp mọi thứ hiệu quả hơn.
Sẵn sàng mở rộng dự án scraping của bạn? Hãy khám phá các giải pháp proxy Python miễn phí hoặc trả phí để bắt đầu ngay hôm nay.




